预训练的概念受到人类生物的启发,由于先天的能力,我们不需要从头开始学习一切。相反,我们转移和重用我们过去学到的旧知识来理解新知识,处理各种新任务。
在人工智能中,预训练模仿了人类处理新知识的方式。即:使用以前学过的任务的模型参数来初始化新任务的模型参数。通过这种方式,旧的知识帮助新的模型,从旧的经验而不是从头开始执行新的任务。
预训练将模型学习分为两部分:
- 半监督学习(共性学习):使用未标注数据对模型进行训练;
- 监督学习(特性学习):使用标注数据对上一步得到的模型进行微调;
也许现在这两句话有些难以理解,没关系,我们将在接下来逐渐详细展开这一概念。
Word2vec
本节参考自 Chris McCormick. Word2Vec Tutorial-The Skip-Gram Model1以及 Lilian Weng. Learning Word Embedding2
Word2vec由Mikolov et al.于2013提出3,使用了一种巧妙的思路对单词进行编码:我们的模型拥有隐藏层和输出层,并用一个“虚假任务”对模型进行训练,在训练完成之后将输出层“掀开”,隐藏层的输出就是我们期望的单词编码。
编码的目的是将单词映射到$N$维空间中,编码后的结果应能够很好的反应单词本身的含义,如相同含义的单词在空间内彼此接近,他们在空间中的距离应该能够与单词本身的相似程度相对应。
Word2vec可分为:Skip-Gram Model与Continuous Bag-of-Words (CBOW)两种,前者使用target word预测context,后者使用context预测target word,接下来仅讨论Skip-Gram Model。
Fake Task
在Skip-Gram Model中,虚假任务定义为:针对某个单词,输出其他单词是其上下文的概率。
其中上下文使用滑动窗口提取,举个例子:
- “The quick brown fox jumps over the lazy dog.”
| Sliding window(size = 5) | Target word | Context | Training Samples(Skip-Gram) |
|---|---|---|---|
| [The quick brown] fox jumps over the lazy dog. | the | quick, brown | (the, quick), (the, brown) |
| [The quick brown fox] jumps over the lazy dog. | quick | the, brown, fox | … |
| [The quick brown fox jumps] over the lazy dog. | brown | the, quick, fox, jumps | … |
| The [quick brown fox jumps over] the lazy dog. | fox | quick, brown, jumps, over | … |
| … | … | … | … |
Model Details
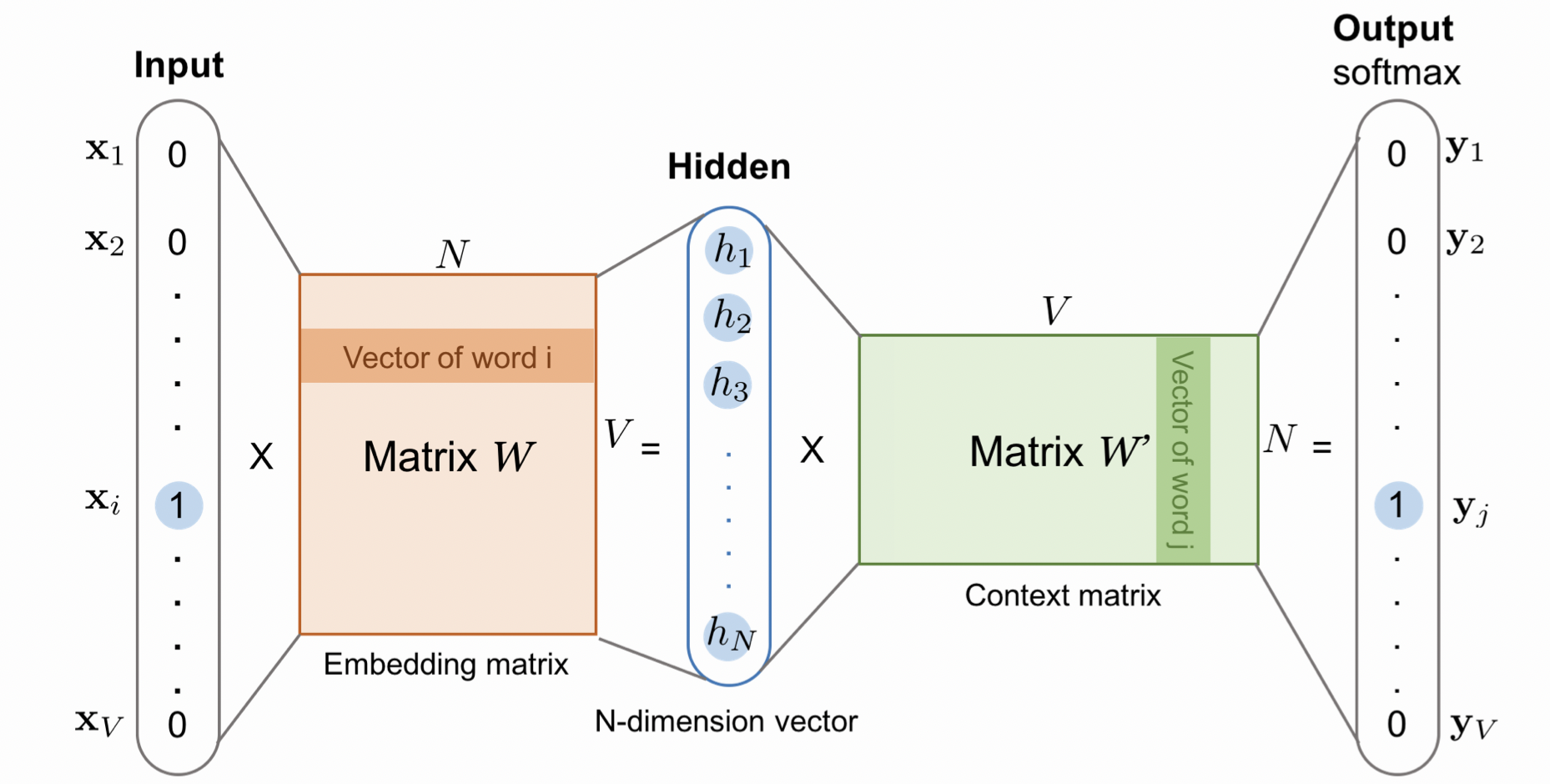
(图源:Lilian Weng. Learning Word Embedding2,我想这是我写笔记为止见到的非常详细清楚的一张图了!)
输入的$x$是一个$V$维one-hot编码,即只有一个位置为1;接下来与embedding matrix做矩阵相乘,选中embedding matrix中的对应$i$行,得到一个$N$维向量,此步代表了对原单词的编码;接下来是输出层,我们将$N$维向量与context matrix相乘,context matrix的$j$列可以看作是第$j$个单词对应当前target word的权重,相乘得到$\hat{y}$ 为$V$维softmax概率,即对应位置单词为target word上下文的概率;对于每个训练样本,预期的输出$y$是单词上下文的one-hot编码。
训练完成后的hidden layer中的embedding matrix存储了我们所有单词的对应编码;
该基础的网络模型在字典 (字典包括了所有的单词)极具增大时工作的不尽如人意,假设我们有10, 000个单词,每个单词有$N = 300$特征。网络模型包括两层:隐藏层和输出层,每层都将有$300 \times 10, 000$个权重!在这么大的神经网络上运行梯度下降是很慢的,更糟糕的是,需要大量的训练数据来调整这么多的权重,避免过度拟合,数百万的权重乘以数十亿的训练样本,训练该模型将是一个灾难。
Word2Vec的作者在他们的第二篇论文4中通过以下创新尝试解决这些问题:
软滑动窗口。意在对较远的上下文分配较少的权重,一种启发式方法是,设定最大窗口大小$s_{max}$,在抽取训练样本的时候窗口大小在$[1, s_{max}]$中随机产生;对频繁出现的词进行子采样。极为频繁的词可能过于笼统,无法区分上下文,另一方面,稀有词更有可能携带独特的信息 (在信息学中的信息编码中有类似的思想)。为了平衡频繁出现的词语和罕见的词语,Mikolov等人建议以一定的概率$1-\sqrt{t/f(w)} $ 丢弃词语;“负采样”。值得注意的一点是,输入以及预期的输出都是one-hot编码,假设目前的训练样本为 (the, brown),在后向传播的过程中,我们将提高context matrix中”brown”对应列的权重,降低其他列的权重,只需要调整embedding matrix的”the”对应行权重。负采样提出为了减少需要调整的参数数目,在更新context matrix时,我们提高”brown”对应列的权重,但仅对部分其他列权重进行降低,实验过程中这部分列数目在5~20。负采样按照如下公式选择那些需要降低权重的列:$P(w_i) = \frac{f(w_i)^(3/4)}{\sum_{i=0}^n f(w_j)^{3/4} }$,其中$f(w_i)$代表该单词出现次数;先学短语。一个短语往往是作为一个概念单位,而不是单个词的简单组成。例如,即使我们知道 “new “和 “york “的含义,我们也不能真正知道 “New York “是一个城市名称。在训练单词嵌入模型之前,先学习这样的短语并将其作为单词单元,可以提高结果的质量。学习短语的一种方式是:$s_{phrase} = \frac{C(w_i,w_j) - \delta }{C(w_i)C(w_j)}$,其中$C(.)$代表计数,$\delta$是阈值,防止学到超低频短语,分数$s$越高,表示成为短语的概率越大,要形成长于两个单词的短语,可以多次执行学习短语程序。
值得注意的是,对频繁出现的词进行子采样和应用负采样等不仅减少了训练过程的计算负担,而且还提高了我们得到的词向量的质量。
ELMo
NLP领域中的预训练思路可以分为两类:
第一代预训练模型专注于word embedding的学习(word2vec),神经网络本身关于特定任务的部分参数并不是重点。其特点是context-free,也即word embedding,每个token的表示与上下文无关,比如“苹果”这个词在分别表示水果和公司时,对应的word embedding是同样的,其中具有代表性的有Word2vec,GloVe等。
第二代预训练模型以context-aware为核心特征,单词的编码不是固定的,而是做为输入的 (包含该单词的) 句子的函数,也就是说“苹果”这个词在分别表示水果和公司时,对应的output是不一样的,其中具有代表性的有ELMo,GPT,BERT等。
在本节,我们将简要介绍ELMo (Em- beddings from Language Models)5的模型基本结构,半监督训练方法等。
Semi-supervised
在Semi-supervised Sequence Learning6中,研究人员介绍了两种使用无标签数据对数据进行预训练的方法,第一种是预测序列中的下一个内容,第二种是使用一个序列编码器,将输入序列编码为一个向量,并预测输入序列。
这两种算法可以作为后来的监督学习算法的“预训练”步骤来使用,即监督学习算法使用预训练得到的模型参数做为起点,实验中的一个重要结果是,在预训练中使用更多相关任务的无标签数据可以提高后续监督模型的泛化能力。例如,使用来自亚马逊评论的无标签数据对序列自动编码器进行预训练可以将烂番茄的分类准确率从79.7%提高到83.3%,相当于增加了大量的标签数据。使用更多的无标记数据进行无监督学习,可以改善监督学习。
ELMo中使用了第一种方法,在预训练中尝试预测序列中的下一个内容,最终的编码是原始编码层输出及多层biLMs层输出的线性加权和。
Bidirectional Language Model
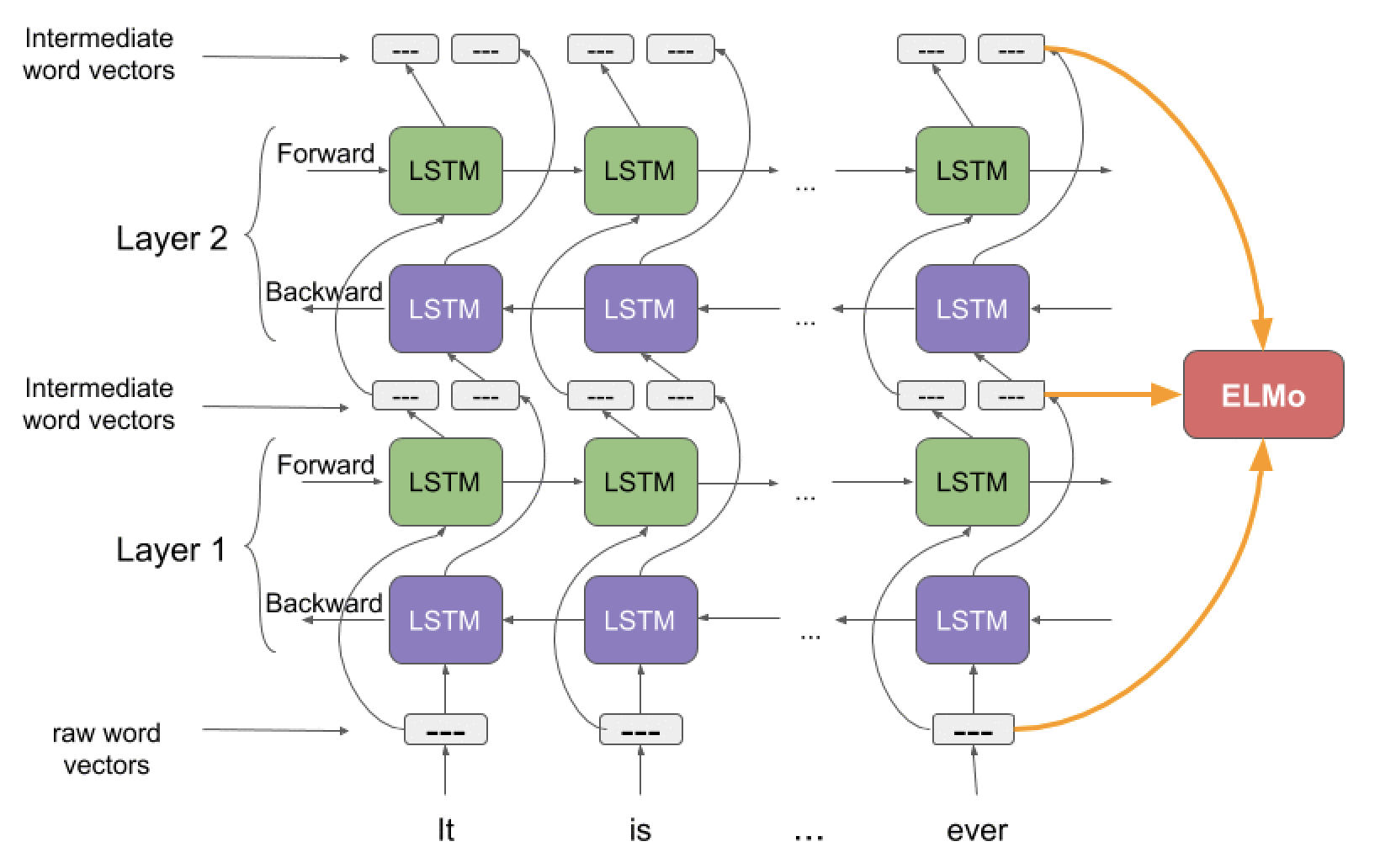
(图源: A Step-by-Step NLP Guide to Learn ELMo for Extracting Features from Text by Prateek Joshi—March 11, 2019)
ELMo模型主要结构由一层单词编码层 (字符级卷积神经网络CNN) 及多层biLMs组成,在顶层biLMs上接一层Softmax输出概率。
设输入序列为$(t_1,t_2,\dots, t_N)$,单词编码层输出为$(x_1, x_2,\dots, x_N)$。
输出的单词出现概率由前后向上下文预测:
\[p(t_1, t_2,\dots,t_N) = \sum_{k=1}^{N}p(t_k | t_1, t_2, \dots, t_{k-1}) \\ p(t_1, t_2,\dots,t_N) = \sum_{k=1}^{N}p(t_k | t_{k+1}, t_{k+2}, \dots, t_{N})\]最大化当前单词的出现概率,可以转换为最小化下式
\[\mathcal{L} = - \sum_{k=1}^{N}( \log p(t_k | t_1, t_2, \dots, t_{k-1};\Theta _x, \overrightarrow{\Theta}_{LSTM}, \Theta_s ) + \log p(t_k | t_{k+1}, t_{k+2}, \dots, t_{N};\Theta _x, \overleftarrow{\Theta}_{LSTM}, \Theta_s))\]其中,$\Theta x$代表单词编码层模型参数,$\overrightarrow{\Theta}{LSTM}$ 、\(\overleftarrow{\Theta}_{LSTM}\)代表多层LSTM模型参数,$\Theta_s$ 代表Softmax层模型参数。由于原始词向量是由字符级而不是单词级产生的,biLM可以捕捉到单词内部结构,能够找出像beauty和beautiful这样的术语在某种程度上是相关的,甚至不用看它们经常出现的上下文。
ELMo Representations
设当前单词$t_k$,共有$L$层biLM,则ELMo共有 $2L+1$个输出,
\[\begin{align} R_k &= \{ x_k^{LM}, \overrightarrow{h}_{k,j}^{LM}, \overleftarrow{h}_{k,j}^{LM} | j=1,\dots,L \} \notag \\ &= \{ h_{k,j}^{LM} | j=0, \dots,L|\}\notag \end{align}\]其中$h_{k,0}^{LM}$代表原始编码层,$h_{k,j}^{LM} = [\overrightarrow{h}{k,j}^{LM}, \overleftarrow{h}{k,j}^{LM}]$代表biLM层。
ELMo将$R$做加权和,概括为单个向量
\[ELMo_k^{task} = E(R_k; \Theta^{task}) = \gamma^{task} \sum_{j=0}^{L}s_j^{task}h_{k,j}^{LM}\]其中$s_j^{task}$为softmax归一化权重,$\gamma^{task}$允许任务模型对整个$ELMo$向量进行缩放,$\gamma$对帮助优化过程具有实际意义,详见原论文5。
ULMFiT
在ULMFiT7中,研究人员首次提出LM + task-specific fine-tuning的训练策略,步骤如下
(1)使用无标签数据预训练LM模型
(2)针对目标任务对LM进行微调
Discriminative fine-tuning由于LM的不同层捕获不同类型的信息 (见ELMo原论文5)。ULMFiT建议用不同的学习率来调整每一层,${η_1,…,η_ℓ,…,η_L}$,其中$η$是第一层的基本学习率,$η_ℓ$是第$ℓ$层的学习率,总共有$L$层。Slanted triangular learning rates (STLR)首先线性增加学习率,然后线性衰减。增加阶段很短,这样模型可以快速收敛到适合任务的参数空间,而衰减期很长,可以更好地进行微调。
(3)预训练的LM增加了两个标准的前馈层,并在最后进行softmax归一化以预测目标标签分布,对目标任务分类器进行微调。
Concat pooling,提取隐藏状态历史上的最大投票和平均投票,并将它们与最终的隐藏状态串联起来。Gradual unfreezin,指从最后一层开始逐步解冻模型。最后一层被解冻并微调一epoch,然后下一个较低的层被解冻,循环该过程知道所有层微调完成。
GPT
GPT使用transformer的decoder创建了一种基础的通用框架,可以将预训练好的模型直接用于许多downstream task。
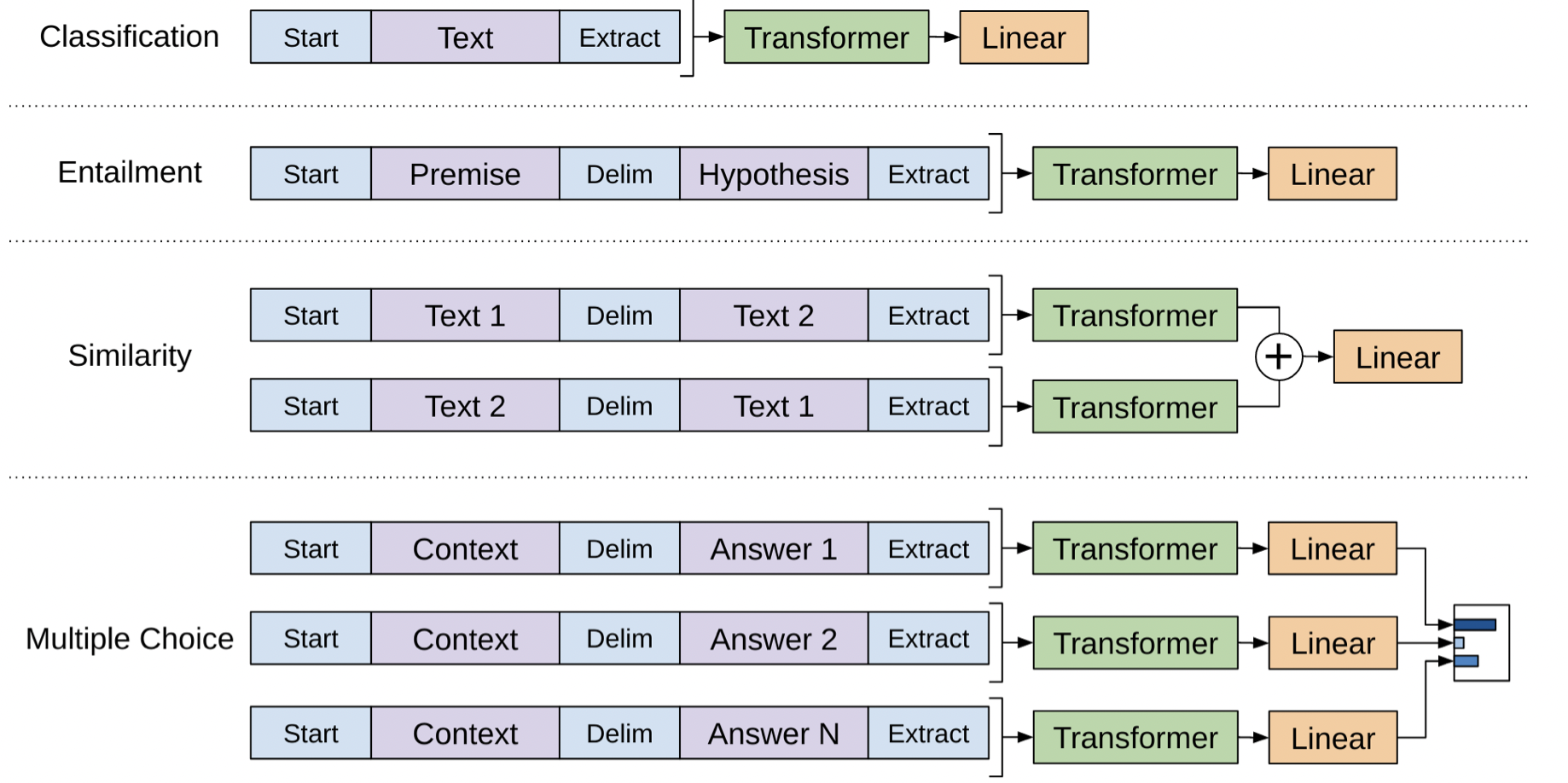
(图源: 原论文8)
GPT同样分为预训练及微调两部分。
Unsupervised pre-training
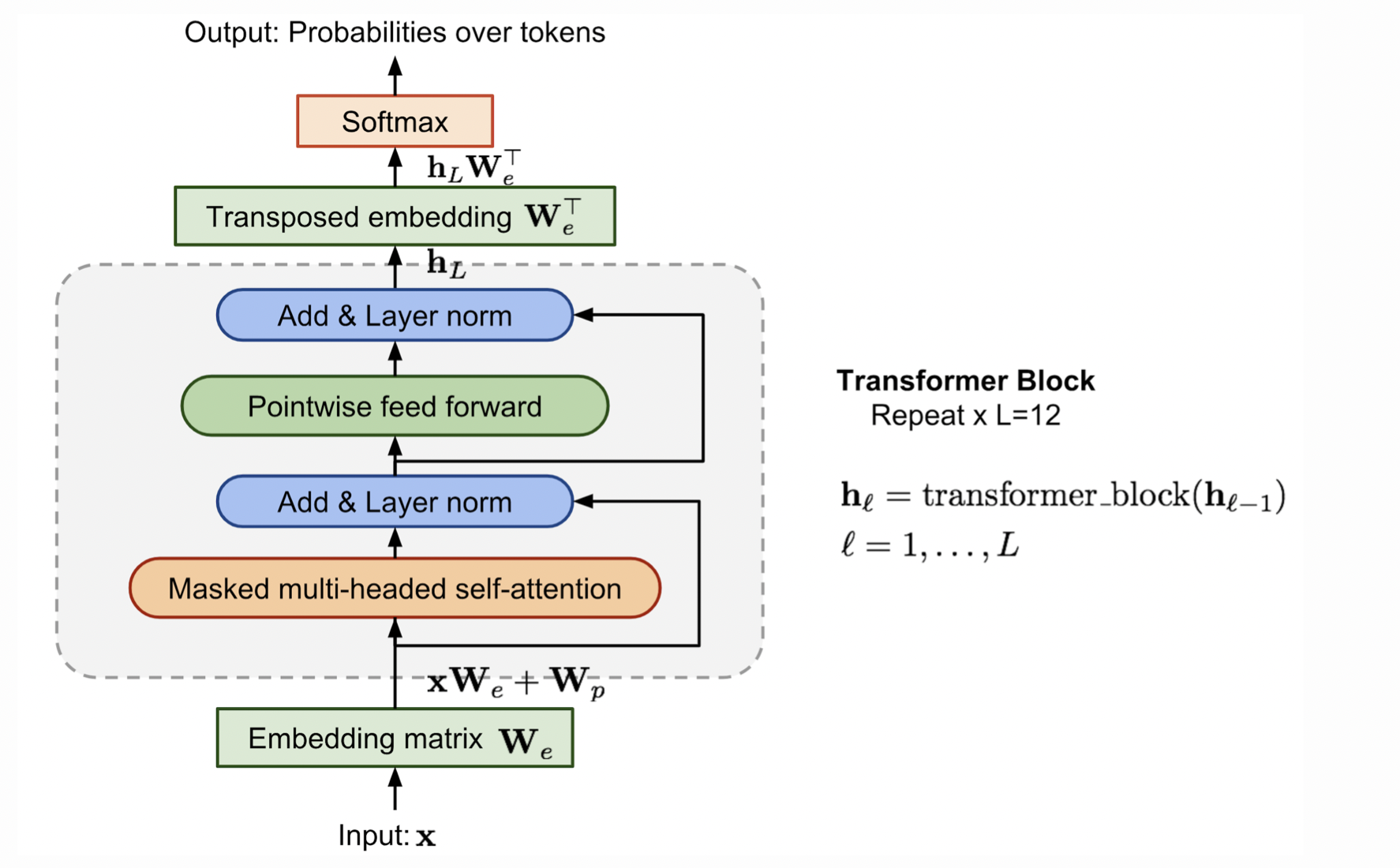
(图源:Lilian Weng. Learning Word Embedding2)
GPT在transformer的decoder之上添加了embedding层及softmax层,只关注过去的上下文信息,loss计算如下 (设窗口大小为$k$)
\[\mathcal{L}_{LM} = - \sum_i \log p(x_i | x_{i-k}, \dots, x_{i-1} )\]Supervised fine-tuning
以分类任务为例

设输入为$(x_1, \dots, x_n)$,标签$y$,GPT将$(x_1, \dots, x_n)$输入到预训练好的transformer decoder中,最后一层隐藏层对于$x_n$输出为$\mathbf{h}_L^{(n)}$ ,使用它预测标签。
\(P(y|x_1, \dots, x_n) = softmax(\mathbf{h}_L^{(n)} \mathbf{W}_y)\)
loss由两部分组成,增加LM损失作为辅助损失有以下效益:在训练期间加速收敛,提高监督模型的泛化能力。
\[\begin{align} \mathcal{L}_{cls} &= \sum_{(\mathbf{x},y) \in \mathcal{D}} \log P(y|x_1, \dots, x_n) = \sum_{(\mathbf{x},y) \in \mathcal{D}} \log \text{softmax}(\mathbf{h}_L^{(n)}(\mathbf{x})\mathbf{W}_y) \notag \\ \mathcal{L}_{LM} &= -\sum_i \log p(x_i| x_{i-k}, \dots, x_{i-1}) \notag \\ \mathcal{L} &= \mathcal{L}_{cls} + \mathcal{L}_{LM} \notag \end{align}\]有了类似的设计,其他downstream task就不需要定制模型结构了。如果任务输入包含多个句子,则在每对句子之间添加一个特殊的分隔符($),这个分隔符的嵌入是我们需要学习的一个新参数。总的来说,在微调过程中,我们需要的唯一额外参数是$W_y$ ,以及分隔符标记的嵌入。
需要提一点的是,早期的研究者们在模型结构上做的尝试比较多,比如ELMo使用了双向LSTM。然而在Transformer出现后,研究者们研究的重点就从模型结构转移到了训练策略上。比如GPT和BERT都是基于Transformer结构的: GPT基于Transformer decoder,而BERT基于Transformer encoder。
-
Word2Vec Tutorial-The Skip-Gram Model - 11 Jan 2017 by Chris McCormick ↩︎
-
Learning Word Embedding - Oct 15, 2017 by Lilian Weng ↩︎ ↩︎2 ↩︎3
-
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013). ↩︎
-
Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013. ↩︎
-
Matthew E. Peters, et al. “Deep contextualized word representations.” NAACL-HLT 2017. ↩︎ ↩︎2 ↩︎3
-
Dai, Andrew M., and Quoc V. Le. “Semi-supervised sequence learning.” Advances in neural information processing systems28 (2015): 3079-3087. ↩︎
-
Howard, Jeremy, and Sebastian Ruder. “Universal language model fine-tuning for text classification.” arXiv preprint arXiv:1801.06146 (2018). ↩︎
-
Alec Radford et al. “Improving Language Understanding by Generative Pre-Training”. OpenAI Blog, June 11, 2018. ↩︎